Data Lineage Guide: Where Does Your Data Come From and Go?

Data lineage is like creating a roadmap for your data: tracing its origins, and understanding how it transforms as it travels through your systems. When executed effectively, data lineage can empower your data engineering (and even business) teams like a superpower. In this article, you will learn more about benefits from a data and business perspective. How does it help you work with data, and how can finance leaders improve trust in their metrics? On top of that, you get tips on how to maximize the value of your data lineage.
What is data lineage?
Data lineage shows the structure of your data landscape, revealing the intricate relationships between different data elements. To keep things simple, let's use an analogy.
The coffee analogy: Visualizing data lineage in action
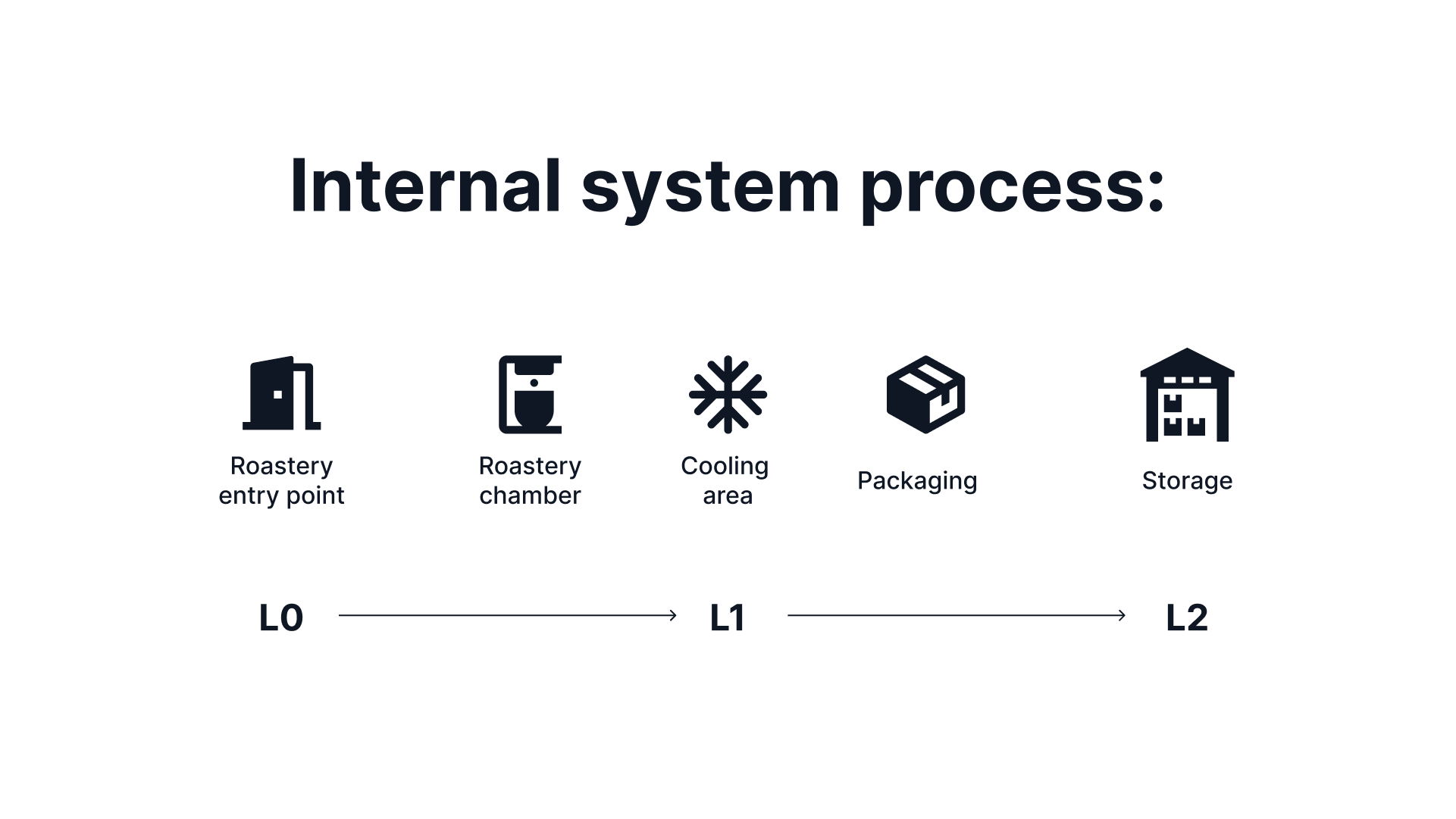
How far does coffee have to travel before it appears in the cup in front of you at your favorite coffee shop? Imagine a coffee farmer, the source system in our analogy. The farmer harvests the coffee beans, which represent the raw data. These beans are then sold to a roastery, analogous to the data warehouse. Within the roastery, the beans undergo various steps, mirroring the transformations that data undergoes. Each step involves intermediate processes, akin to data pipelines.
The initial entry point into the roastery is L0, where the beans are received, inspected, and weighed before being recorded in a database (intermediate processes). From there, the beans move into the roasting process itself, represented by L1. Roasting involves a data pipeline that transfers the beans from the entry point to the roasting chamber, then to the cooling area, and finally to the packaging stage. The entire batch of roasted beans is then stored in L2, the outbound warehouse, awaiting distribution. This entire process represents an intra-system lineage.
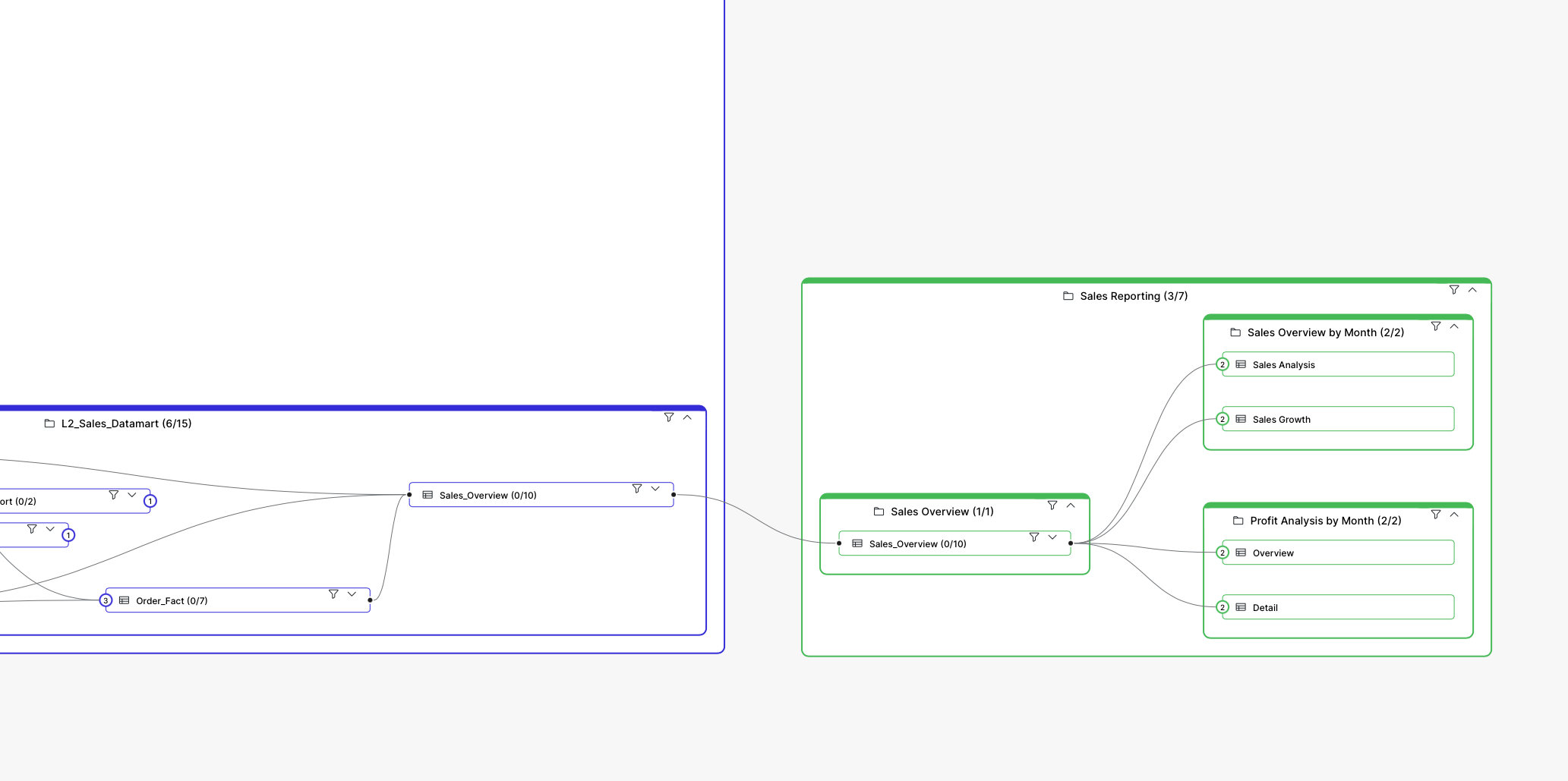
The data journey doesn't always end within a single system. It often extends to other systems, such as reporting tools like PowerBI. In this scenario, the roasted coffee beans are transported from the roastery to a café, analogous to data flowing into a reporting system. The café has its own internal processes and tables that handle the coffee data, potentially dividing it based on coffee machines, shifts, or other factors. The coffee continues to flow through the cafe's system, guided by its unique data pipelines (because it's a different layer than when we were at the roastery).
While this simplified analogy provides a glimpse into data lineage, real-world data landscapes are far more intricate, involving numerous systems and transformations. Manual tracking of data lineage in such complex environments becomes an arduous and time-consuming task.
Data lineage is not just about tracking data movement; it's also about understanding how data changes as it moves. A critical component of data lineage is the ability to visualize and understand data transformations.
It shows you the entire process:
- Where the beans came from (source system): Were they grown in a specific region, perhaps in South America?
- What steps they went through (transformations): Were they roasted to a specific level (light, medium, dark)?
- How they arrived at your cup (destination system): Did you buy them whole beans and grind them yourself, or did they come pre-ground?
This information is crucial for ensuring the coffee's quality. Data lineage helps you identify any potential issues, like beans that weren't roasted properly or sat on the shelf for too long.
What is a data transformation?
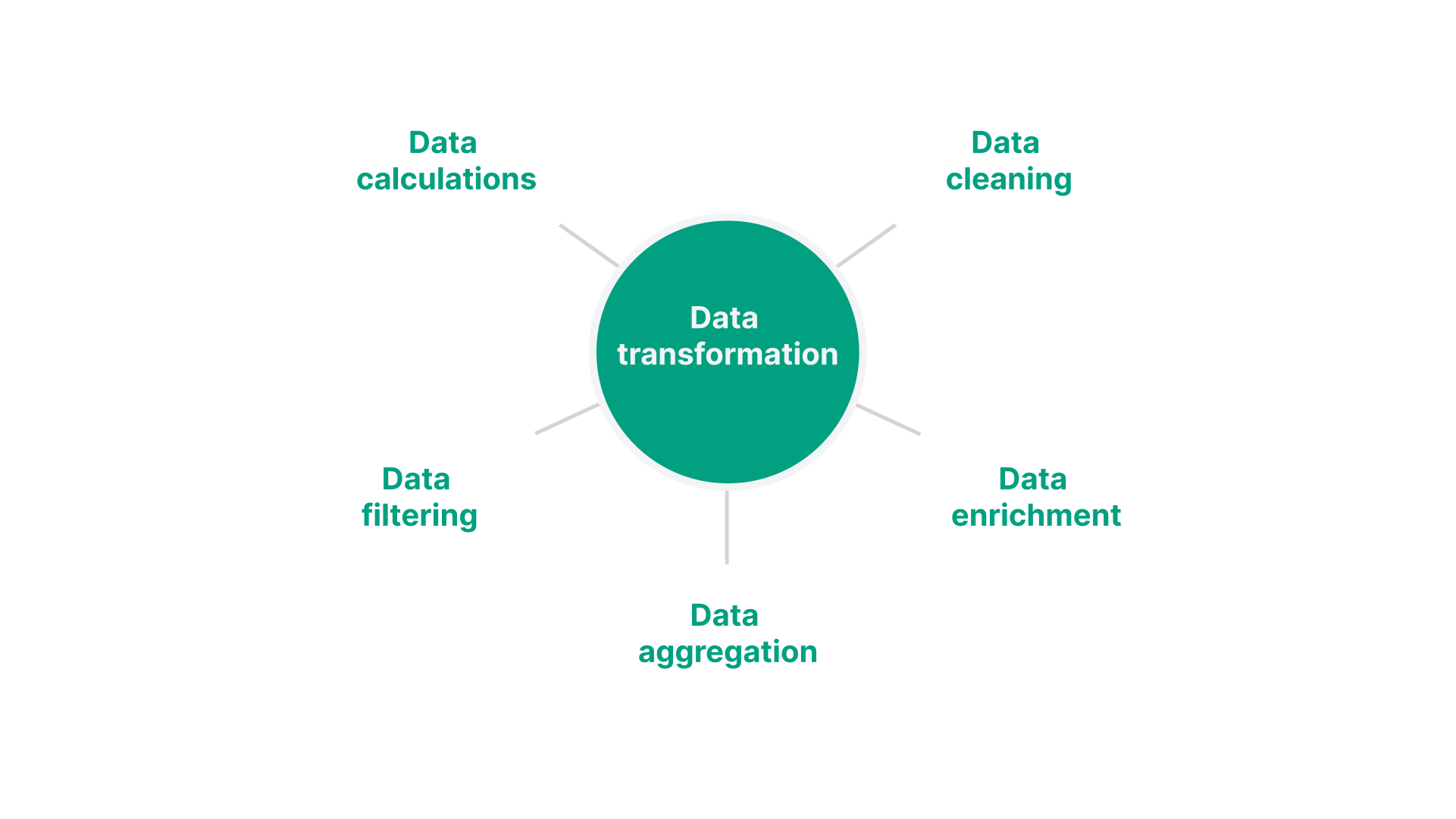
A data transformation is any process that alters data, changing its format, structure, or content. This could include:
- Data cleaning: Removing errors, inconsistencies, or duplicates.
- Data enrichment: Adding new data elements or attributes.
- Data aggregation: Combining data from multiple sources.
- Data filtering: Selecting specific data based on certain criteria.
- Data calculations: Performing mathematical or statistical operations.
So, what is data lineage in practice?
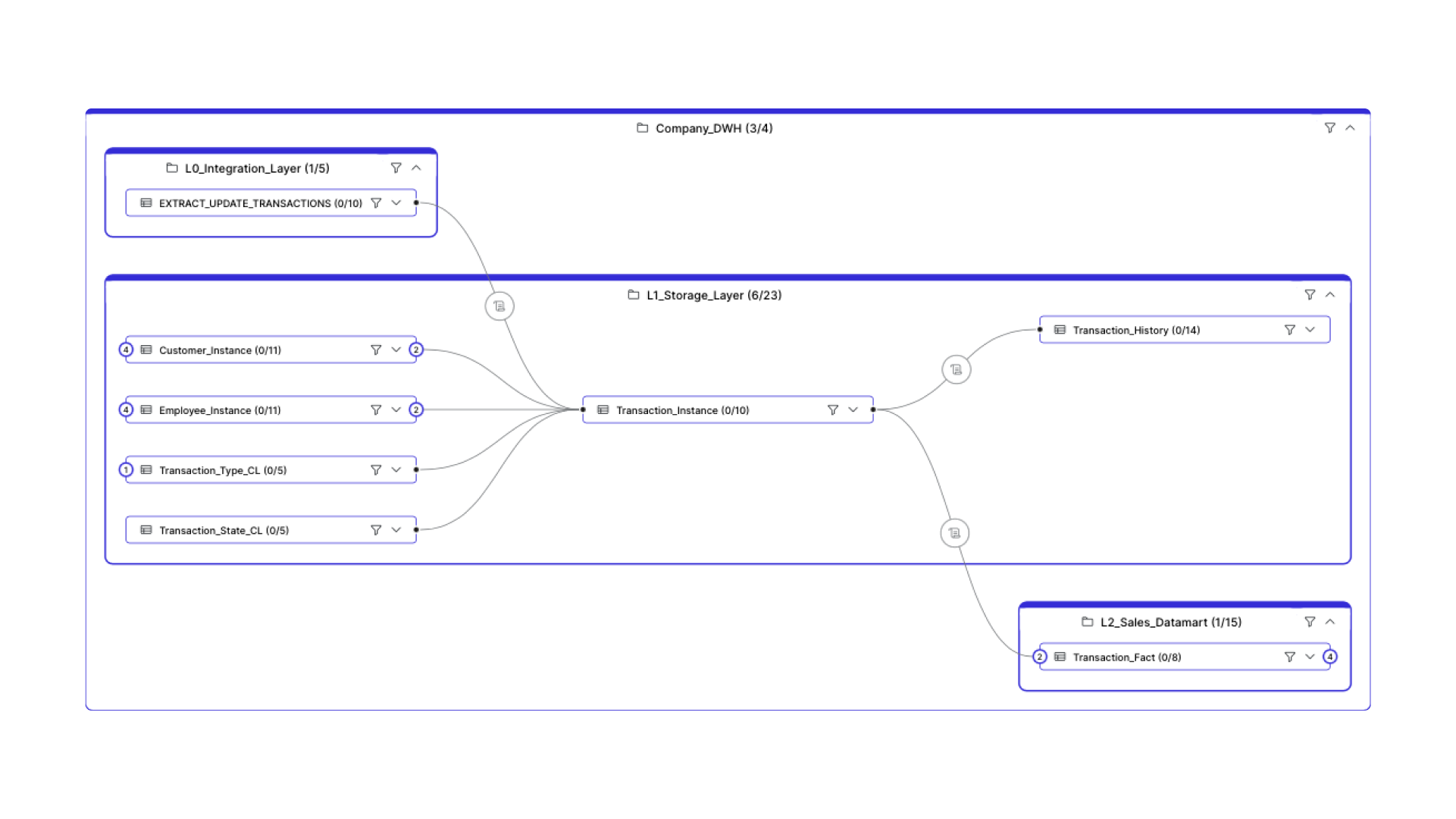
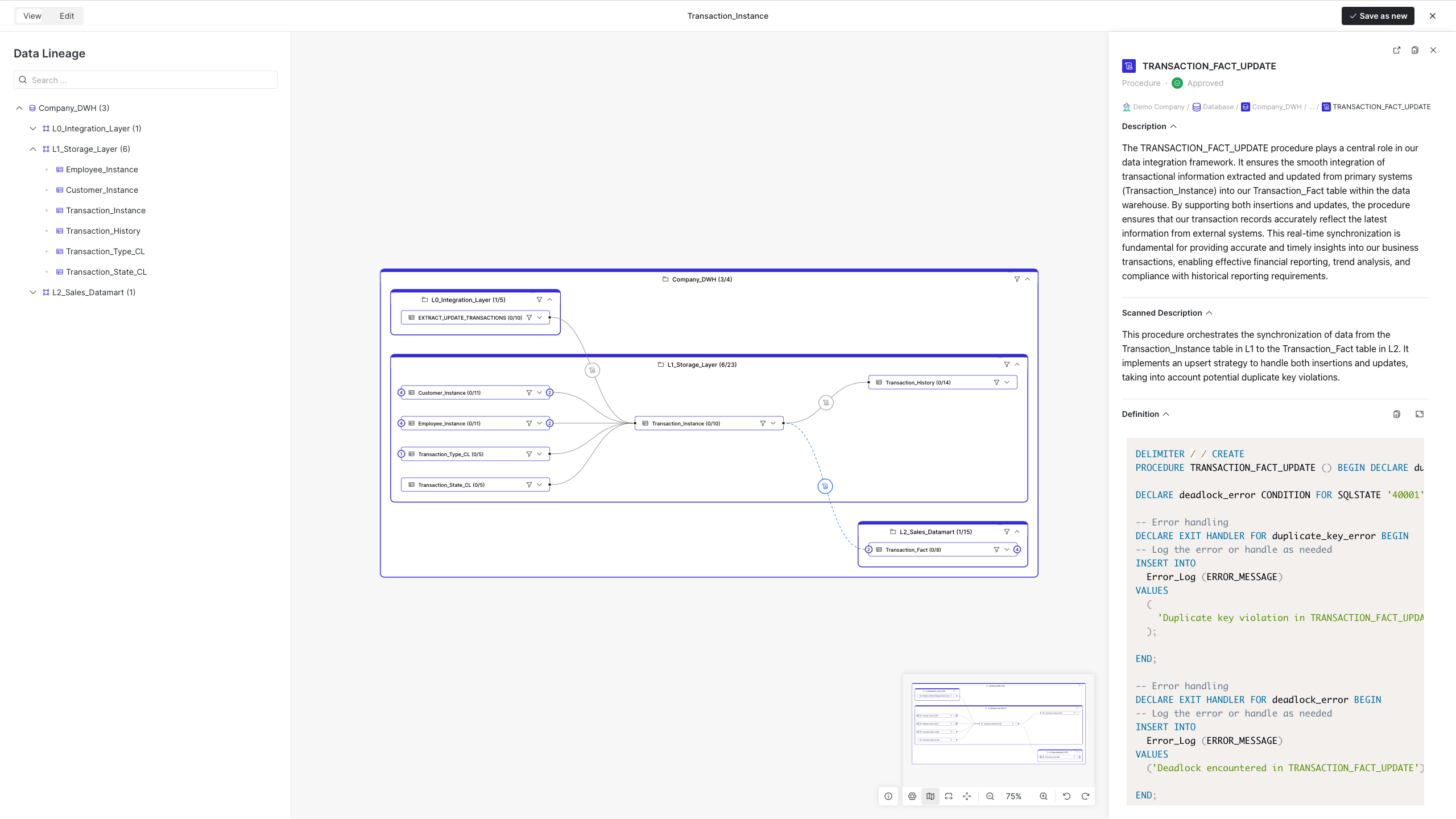
Imagine your data are organized into large "folders", each representing a system, data warehouse, or database. Folders are the highest-level objects visualized in the data lineage diagram. Within each warehouse, you may encounter multiple layers. Such as L0, L1 and L2 (as shown in the figure below). When L0 serves as a staging area for data extracted from source systems (the first stage in that concrete layer - internal system). These DWH layers play a pivotal role in data transformation. Data is often copied into L0 in a 1:1 manner from the source system, before undergoing transformations and being stored in L1.
Data is extracted from the source system (similar to a farmer harvesting crops) through an ETL process. This process transfers the data to a data warehouse (our 'roaster'). From there, it's used to generate reports and support analytical tools like data science models.
Each table within your system relies on data from other tables, sometimes drawing from multiple sources. Data lineage unveils these intricate connections, revealing the exact tables that contribute to a particular table's data. This visibility extends further, tracing the data flow through subsequent tables and layers.
Why is Data Lineage Important?
It is important especially for data engineers and data analysts. It empowers them to conduct impact analysis, a critical process that traces the flow of data from a specific point (like a table) to its final destinations within the system. This understanding of upstream and downstream dependencies is key to efficient incident resolution.
Imagine this: an incident occurs, causing data inconsistencies. With data lineage in place, you can quickly pinpoint the affected areas and their impact. This allows for faster notification of stakeholders and the implementation of effective remedies to fix the data breaks.

Is data lineage necessary for every data team?
The short answer is yes. For data teams that are serious about reliability and scaling data quality, data lineage is essential.
Benefits from a data professional's perspective
Data lineage involves tracing the flow of data from a specific table to its final destination within the system. This capability proves invaluable in scenarios like:
- Renaming a column: When a column name needs to be changed due to a typo or error, data lineage can identify all downstream systems or processes that might be affected by this change.
- Identifying data discrepancies: If an incorrect value is discovered at the end of the data pipeline, data lineage can be used to trace back the source of the error and pinpoint the specific transformation or process that introduced the discrepancy.
- Validating data loading procedures: Data lineage can be employed to verify the integrity of data loading procedures, ensuring that data is being loaded correctly and consistently.
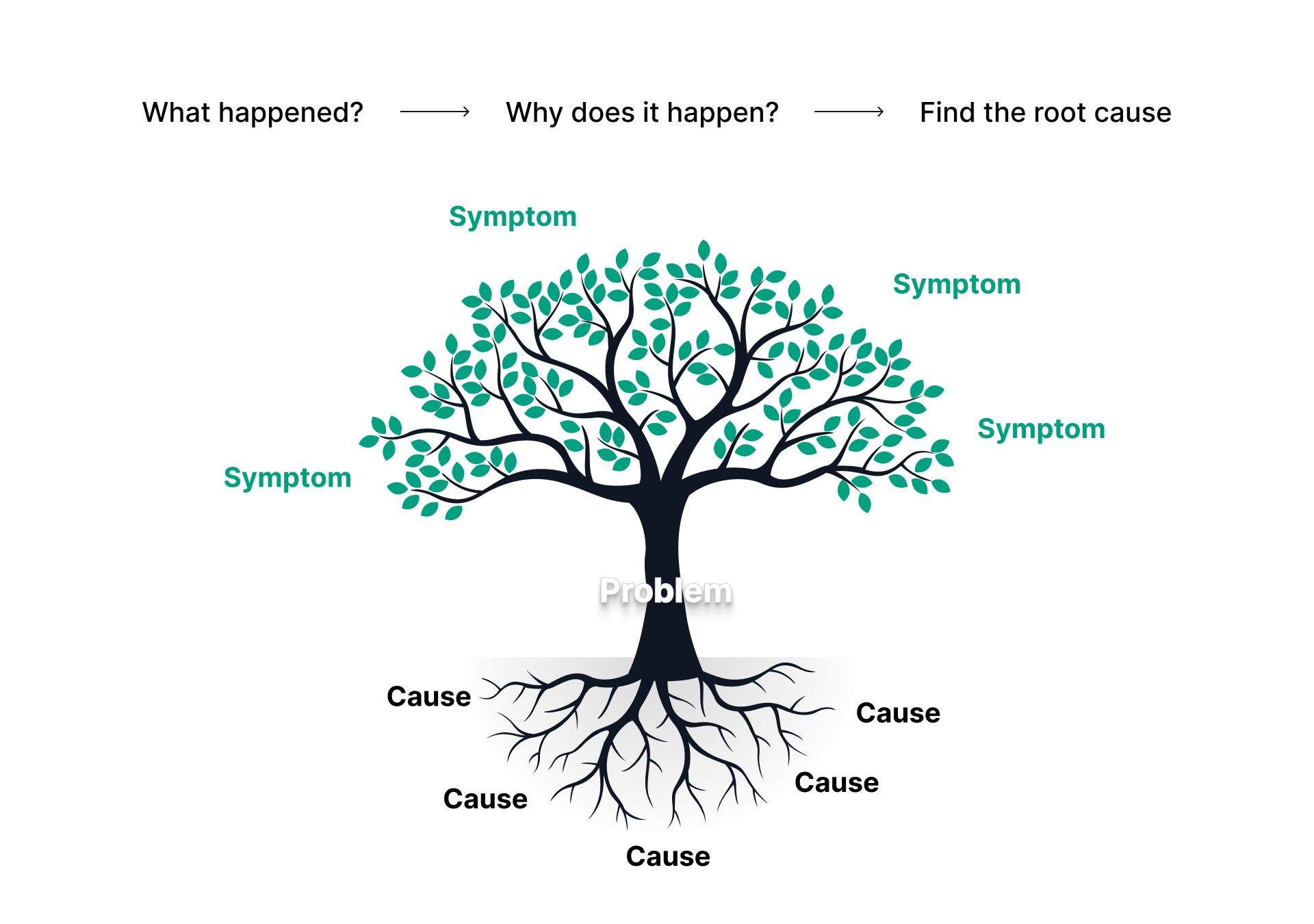
Thanks to it we can understand the "why" behind data issues, facilitating efficient troubleshooting and root cause analysis.
Is data lineage necessary for the finance department?
Sure. Even those who don't directly work with the data rely on its accuracy for tasks like budgeting, forecasting, and financial reporting. Data lineage provides a department-wide understanding of the data's journey, fostering trust in financial decisions and minimizing risks.
For financial data teams, it simplifies regulatory compliance and helps identify the downstream impact of data issues. This transparency empowers assured decisions and reduces risk.
Benefits from a business perspective
Data Lineage for Metrics and KPIs: Unraveling the Data Behind the Numbers
Data lineage plays a crucial role in understanding the data sources that underpin metrics and KPIs, particularly those critical for financial leadership. Consider a profit analysis report generated monthly, with an overview page displaying six metrics derived from various data sources. Data lineage can precisely reveal the data elements and tables that contribute to each metric. For instance, the "number of customers" metric can be traced back to specific columns in a particular table, which in turn draws data from another table.
Troubleshooting Data Issues: Identifying the Root Cause
When discrepancies arise in metrics like customer count, data lineage empowers you to pinpoint the exact source of the error within the system. By visualizing the data flow and transformations, you can identify the specific point where the data integrity is compromised.
Conclusion of main benefits:
- Map data flow across systems and layers: Gain a comprehensive understanding of how data moves through your data landscape.
- Identify data sources for metrics and KPIs: Unravel the data behind your critical business indicators.
- Pinpoint the root cause of data issues: Quickly identify discrepancies and errors within your data pipelines.
- Demonstrate data compliance: Showcase data traceability and adherence to data governance regulations.
- Improve data quality: Ensure data integrity and consistency throughout your data lifecycle.
- Boost collaboration and decision-making: Foster better communication and data-driven decision-making across teams.
Tips for maximizing the value of data lineage
Add context
Enrich data lineage with business definitions, data quality scores, and other relevant details. This contextualizes the data and makes it more meaningful. By including business definitions in data lineage, you're essentially connecting the technical details of the data flow with the actual business meaning behind it. This bridges the gap between technical users and business users.
With the right metadata for a given data asset included in the lineage itself, you can get the answers you need to make informed decisions:
- Who owns this data asset?
- Where is this asset located?
- What data does it contain?
- Is it relevant and important to stakeholders?
- Who relies on this asset when I make a change to it?
You can use data lineage together with business glossary. Data lineage provides the technical roadmap of the data, and the business glossary provides the key to understanding the business significance of each stop on that map. They work together to create a more comprehensive and valuable picture of your data.
What are the implications?
From a business perspective, data lineage enhances data trust. It goes beyond simply having numbers without understanding their origin. By combining business definitions from a business glossary with the knowledge of where the data for those numbers originates, we can establish the veracity of the data. This, in turn, fosters trust in the data.
Business users can leverage data lineage to gain insights at the database level, rather than delving into the complexities of tables and columns. A simplified view facilitates better comprehension and decision-making.
Automation
As your data ecosystem grows, ensure your data lineage practices can keep up. The emergence of machine learning has revolutionized data lineage. Vendors now offer automated solutions that handle lineage tracking at a massive scale, a feat previously impossible with manual processes. Look for automated tools and scalable solutions.
Manually tracking data lineage for a complex data ecosystem quickly becomes overwhelming. It requires significant time and effort to track data movement across numerous sources, transformations, and destinations. It can lead to inaccurate or outdated lineage information.
Automated tools capture data lineage information automatically, freeing up your team's time for analysis and other strategic tasks. It minimizes human error and ensures your data lineage reflects the current state of your data pipelines.
Metadata management platforms provide scalable solutions to manage data definitions and relationships, including data lineage information. They can integrate with your data pipelines for automated tracking.
PNG Exports for easy sharing
With Dawiso, you can not only visualize data lineage but also effectively communicate its intricacies to stakeholders. The ability to export data lineage diagrams as PNG images provides a convenient way to share and discuss data flow with others. It allows you to also add annotations to your data lineage diagrams. These annotations can include definitions, explanations, or any additional information that helps to clarify the purpose and significance of specific data elements or transformations. Providing context is particularly valuable when communicating with non-technical stakeholders or regulators.


