Decentralized Data Architecture and How Data Products Fit In

Decentralized data architecture is redefining data management by focusing on data products as the primary units of value. This article dives into the role of data products within data warehouse architecture, contrasting traditional approaches with the innovative data mesh model. To better grasp the concept of data products and their importance, we recommend reading What Are Data Products and Why Does Your Business Need Them? first—it will provide helpful context for understanding the ideas presented here.
What is decentralized data architecture?
Decentralized data architecture is built on several key components that work together to create a scalable and efficient system for managing data across an organization. At its core are domains representing different business areas such as marketing, sales, or operations. Each domain is responsible for managing its own data, treating it as a product that must meet standards of quality, accessibility, and usability. This domain-based approach ensures that data ownership is distributed and aligned with the business's specific needs.
The data products themselves are the building blocks of decentralized architecture. Each data product includes not only the raw data but also metadata and mechanisms for secure and easy access. Metadata plays a key role in making data products discoverable, understandable, and trustworthy. It includes documentation about data lineage, and usage guidelines, ensuring that users across the organization can confidently work with the data (you can go more in detail by reading about “Components of Data Products”).
Supporting this structure is the infrastructure, the technical backbone that powers the storage, processing, and access of data products. This includes cloud services, compute resources, and tools for enforcing access control and compliance. The governance framework ensures that while domains operate independently, they adhere to a shared set of rules and policies for data consistency, security, and compliance. This framework defines how data is accessed, shared, and maintained across the organization.
Lastly, interoperability is crucial to the architecture, enabling data products from different domains to integrate seamlessly. Standardized formats, APIs, and consistent data schemas ensure that insights can flow freely and cohesively, empowering collaboration and innovation across the organization. In Dawiso, you can simultaneously manage data products from multiple domains and also multiple platforms from one place.
What are Data Products from the Perspective of Data Warehouse Architecture?
The data warehouse provides the technical foundation for managing data, focusing on storage, processing, and aggregation. While these layers ensure data quality and reliability, they do not inherently provide the business context or reusability that data products in a data mesh aim to achieve.
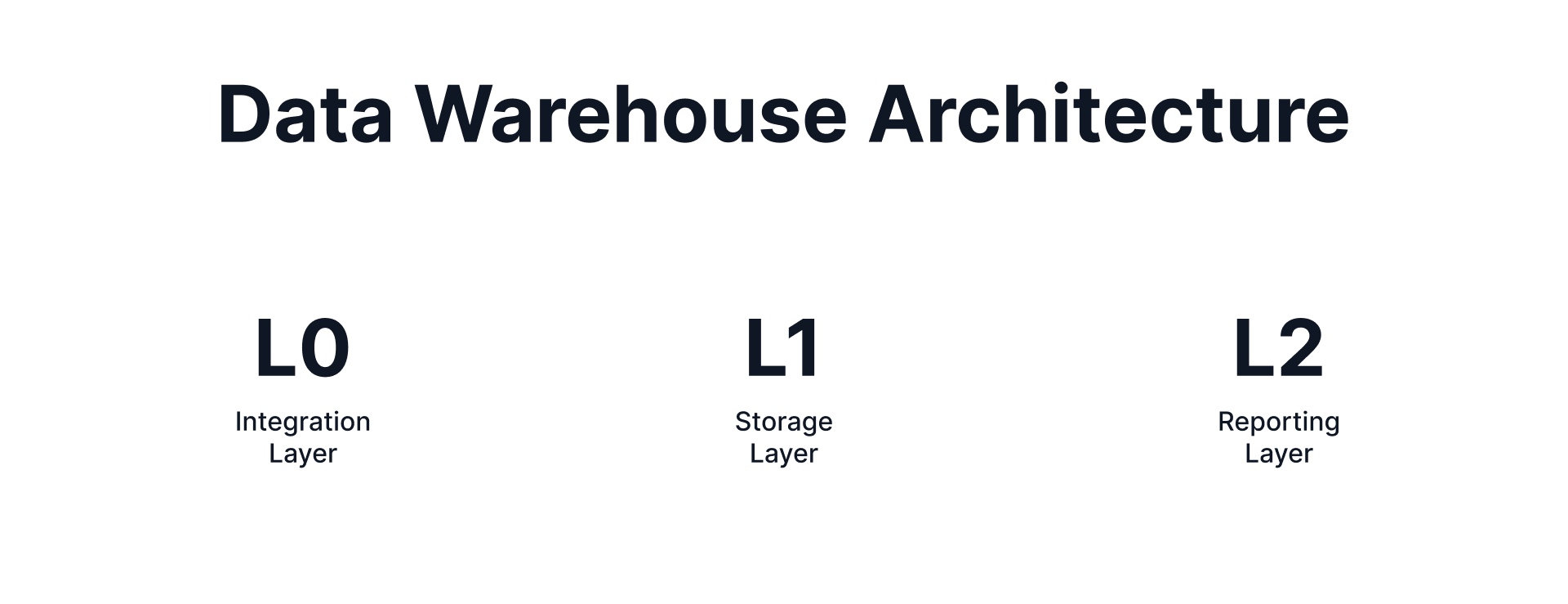
Data warehouses are typically organized into multiple layers. The structure shown in the figure (below) includes three key layers: the Integrative Layer (L0), the Storage Layer (L1), and the Reporting Layer (L2). Each layer serves a specific purpose within the data warehouse architecture.
At its core, the data warehouse stores raw data that is often encoded or formatted in a specific way. This differs fundamentally from the "data mesh" architecture, where data products operate at a higher, business-oriented layer. The data mesh focuses on creating reusable, domain-specific data products, representing a layer that sits conceptually above the data warehouse. Meanwhile, the data warehouse functions as the foundational or "bottom" layer that supports the implementation of data storage and processing.
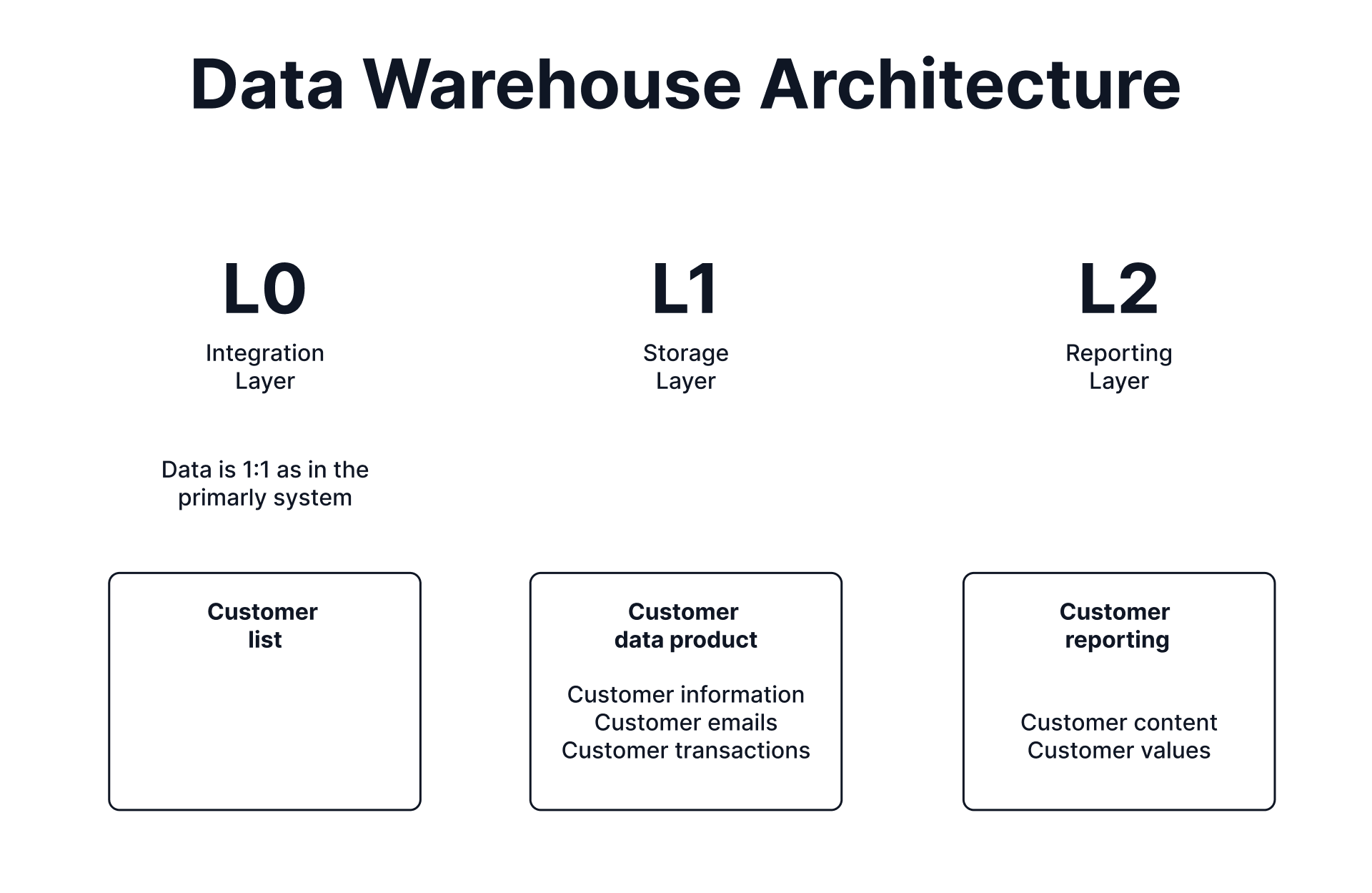
L0 - Integrative Layer: This is the raw data layer, where data is stored as it is ingested from source systems. It represents a 1:1 copy of the data as it exists in the originating systems—whether it's a list of transactions, customers, or email addresses. This layer serves as the unaltered foundation for further processing and transformation within the warehouse.
Once data is ingested into the warehouse, it undergoes transformation and moves into L1, the storage layer. This layer holds processed and organized data, serving as the core of the data warehouse. Unlike L0, which is periodically flushed after ingestion, L1 retains the foundational datasets that form the backbone of the warehouse.
In the reporting layer (L2), data is further aggregated and analyzed to create insights. For example, the total number of customers can be calculated in this layer using customer information stored in L1. L2 is where the data becomes actionable and accessible for business reporting and decision-making.
Now that we understand the data warehouse architecture, we can ask:
"So, what does the data mesh add to this?"
The data mesh builds on the foundation provided by the data warehouse, focusing on wrapping technical tables into reusable, domain-specific data products. By adding this business-oriented layer, the data mesh bridges the gap between raw data storage and actionable insights, empowering teams to work more efficiently and independently.
In a data mesh, the focus shifts from tables to data products, which wrap related tables into a cohesive unit. For instance, the example in the figure illustrates tables such as Customer Information, Customer Emails, and Customer Transactions. Together, these tables form a single Customer data product, with each data product having a defined owner responsible for its quality and maintenance.
Similarly, in the reporting layer (L2), we might have a data product named Customer Reporting, which includes a set of tables used to calculate and store customer metrics. By treating data as products, the data mesh approach bridges the gap between raw data and business use cases, enabling clearer ownership, better organization, and enhanced usability across the organization.
The data tables in L1 and L2 differ significantly in their content and purpose. In L1, the tables contain raw, unprocessed data—the foundation of the entire data warehouse. This is where you can see detailed, historical information about customers, such as when they set up accounts, their account transactions, name changes, and other changes over time. Essentially, L1 holds the raw, granular data that reflects the state of the primary systems.
The Reporting Layer (L2) focuses on aggregating data into actionable insights for reporting and analytics. However, in the data mesh, data products take this a step further by consolidating related insights from multiple layers into cohesive units. For example, tables containing customer metrics, transaction history, and aggregated KPIs can be combined into a 'Customer Reporting' data product, making them easier to understand and use for specific business purposes.
To ensure these reporting tables are accurate and ready for use, data contracts are essential. A data contract guarantees that the data needed for calculations—such as the raw customer data in L1—is available on time. For instance, the contract might specify that the Customer data product will be updated daily and ready by 11 p.m. This agreement ensures reliability and consistency for downstream users relying on L2 for analytics (consuming Customer reporting, charging data from Customer data product).
In essence, L2 draws from L1, transforming raw data into actionable insights, while data contracts ensure the pipeline runs smoothly and data is available when needed.
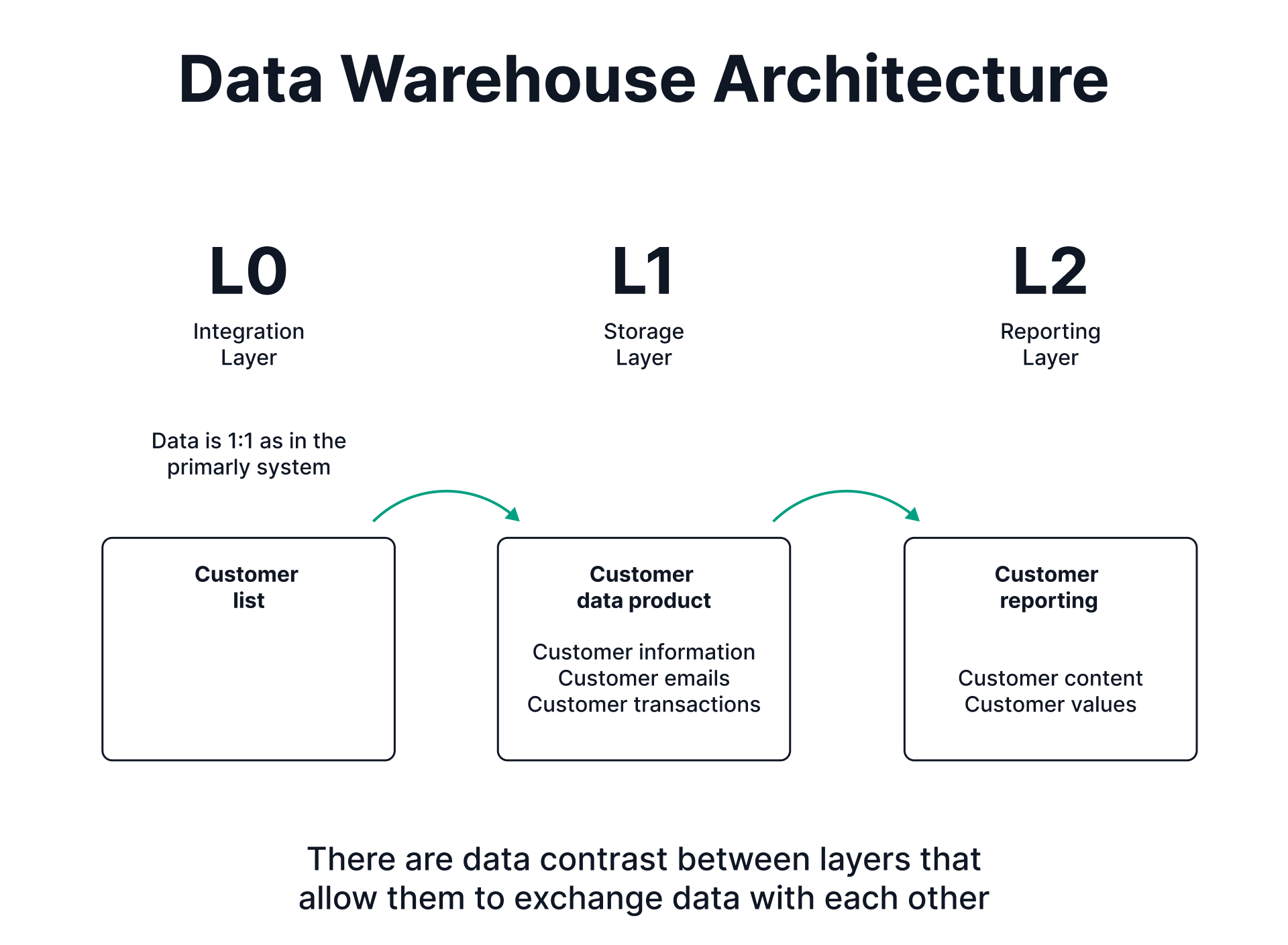
The data contract acts as an agreement between L0 (raw data layer) and L1 (processed data layer), ensuring that the data product in L0 guarantees the preparation of data in a timely manner, with the required quality, so that L1 can process and use it effectively. Depending on how the data mesh is implemented, a data product might span across multiple layers or exist within a single layer.
Data products represent a conceptual business layer that abstracts and organizes related tables across technical layers, making them reusable and accessible for specific business purposes. They are not physical entities coded into the data warehouse but rather an abstract way to organize and think about data. Tools like Keboola can visually represent these data products, making them easier to manage and interact with.
Think of data products as carefully organized boxes containing everything needed for a specific business task—customer metrics, transaction data, and analysis tools—all neatly packaged and ready to use.

Data Products Metaphor: Store with running shoes
Imagine a store that sells running shoes from various brands like Adidas, Nike, and Puma. The store doesn’t manufacture the shoes itself but relies on suppliers to provide them. To ensure consistent stock, the store establishes contracts with these suppliers. These contracts guarantee regular deliveries of the right shoes based on orders or pre-agreed terms.
Similarly, the suppliers have their own agreements with manufacturers, who source materials and produce the shoes. Because this supply chain is well-organized, the store can reliably stock running shoes from multiple brands, meeting customer demand.
In the data mesh, data contracts work in a similar way. They ensure that one data product delivers the required data to another on time and with the necessary quality. For example, a contract might guarantee that raw customer data from L0 is processed and ready for L1 reporting by a specific time. These agreements are implemented through automated pipelines like ETL, ensuring consistent and reliable data flow between products.
This combination of abstraction (business layer) and technical implementation ensures that the data mesh operates efficiently while supporting the needs of the business.
Tools for Supporting Data Mesh
Self-Serve Data Platforms
A self-serve data platform is a cornerstone of the data mesh approach, designed to empower domain teams to manage their data independently while ensuring interoperability, accessibility, and governance. These platforms streamline tasks like data ingestion, transformation, and cataloging through automation, enabling data producers and consumers to work efficiently without heavy reliance on IT. Features such as intuitive interfaces, embedded governance, and interoperability ensure that data products remain accessible, standardized, and secure. This approach supports better data quality, reduces duplication, and facilitates scalability as organizations grow.
Dawiso: Data Governance and Catalog Platform
Features:
- Support developing data products.
- Metadata management, business glossary, and lineage tracking.
- Tools for collaboration, transparency, and democratization of data.
- Focus on usability, affordability, and accessibility for all domains.
- Enable data discovery.
- Institute data governance policies.
Use in Data Mesh: Dawiso can serve as the connective tissue of a self-serve data platform, helping domains document, discover, and govern their data products in alignment with data mesh principles.
Collaboration with other platforms
Our platform allows users to define data products, document them, and make them available in a marketplace-like format. For instance, when integrated with tools like Keboola or Confluent Kafka, Dawiso can automatically generate physical data flows based on user-defined products.
This flexibility supports both centralized and decentralized models, enabling data teams to collaborate while empowering individual business units like marketing or sales to take ownership of their data. Governance remains a critical layer here—without it, decentralized data management can quickly become chaotic.


