What 'AI-Ready Data' Actually Means: A 7-Point Checklist

'AI-ready' is on every vendor slide and almost no one defines it. Here is a concrete, measurable definition: seven checks that decide whether an AI can actually find, trust, and correctly use a dataset, and how to score each one.
Why "AI-ready data" needs a real definition
"AI-ready data" is on every vendor slide and in every board deck, and almost no one says what it means. Used loosely, it signals nothing: every dataset is "AI-ready" if you squint. Used precisely, it is one of the most useful filters a data team has: a concrete bar a dataset either clears or does not, and a list of exactly what to fix when it does not.
This post is the practical version. We will skip the conceptual ground: for the definition itself, see the AI-ready data glossary entry, and for the discipline of assembling context, our guide to context engineering for enterprise AI. What follows instead is a checklist: seven checks that turn a vague aspiration into something you can score, dataset by dataset.
A working definition: find it, trust it, use it
Strip away the marketing and the requirement is simple. Data is AI-ready when an AI can find it, trust it, and use it correctly, without a human stepping in to supply the missing context. Each of those three verbs is where most data fails.
An AI can't find data it can't discover or whose meaning is undocumented. It can't be trusted with data whose origin, quality, sensitivity and ownership are unknown. And it can't use data that no tool can actually read. AI-readiness is the state where all three hold, and the seven checks below are simply those three verbs made specific and measurable.
"AI-ready isn't a property of your model. It's a property of your data."
The AI-ready data checklist
Here are the seven checks. The first one makes data findable; the middle five make it trustworthy; the last one makes it usable by AI tools. None is optional for data an AI will act on, because the AI is only as reliable as the weakest check: a perfect definition still feeds a wrong answer if the data behind it came from a broken pipeline.
Check 1. Cataloged: the AI can find it
An AI cannot use data it cannot discover. The first check is whether the dataset lives in a data catalog, a searchable inventory of what exists across your warehouses, lakehouses, BI tools and operational systems, with the metadata that makes each asset findable. Data scattered across systems with no catalog entry is invisible to AI, which means the AI either ignores it or, worse, reaches for a lesser source it can see.
How to measure it: for a given dataset, can it be found by a keyword or business-term search in a catalog, with its location, schema and basic metadata attached? If discovery still depends on asking a particular person, this check fails.
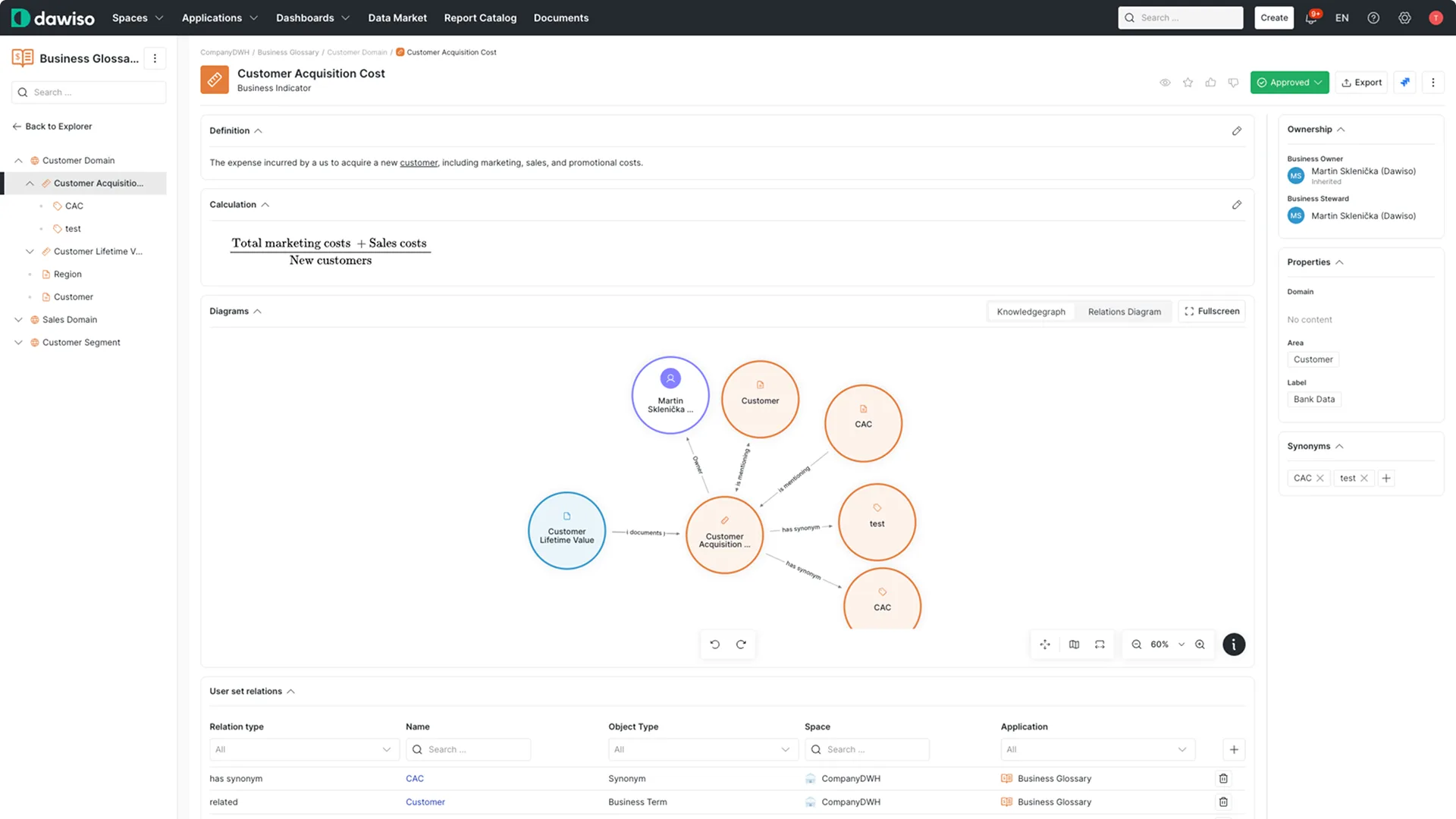
Check 2. Defined: it knows what the fields mean
Finding a table is not understanding it. The second check is whether the data's business meaning is documented in a business glossary: what each metric and entity means, how it is calculated, and the edge cases that trip people up. A column called rev is meaningless until something records that it is net of refunds, in reporting currency, recognized not booked. This is the single highest-leverage check, because undefined data is exactly what makes an AI guess, and guessing the meaning is why text-to-SQL breaks in the enterprise.
How to measure it: do the key metrics and entities in the dataset have approved, owner-authored definitions linked to the underlying columns? If the meaning lives only in tribal knowledge or a stale wiki, this check fails.
Check 3. Classified: it knows what's sensitive
Before an AI uses data, it has to know what it is allowed to do with it. The third check is classification: which fields contain personal data, financial data, or other sensitive information, and what policy governs their use. Without it, a capable assistant will surface a salary table or a customer's personal details to anyone who asks the right question, because nothing told it the data was restricted.
How to measure it: are sensitive fields tagged with a classification and an access policy that travels with the data? If an AI tool could expose regulated data simply because it is reachable, this check fails.
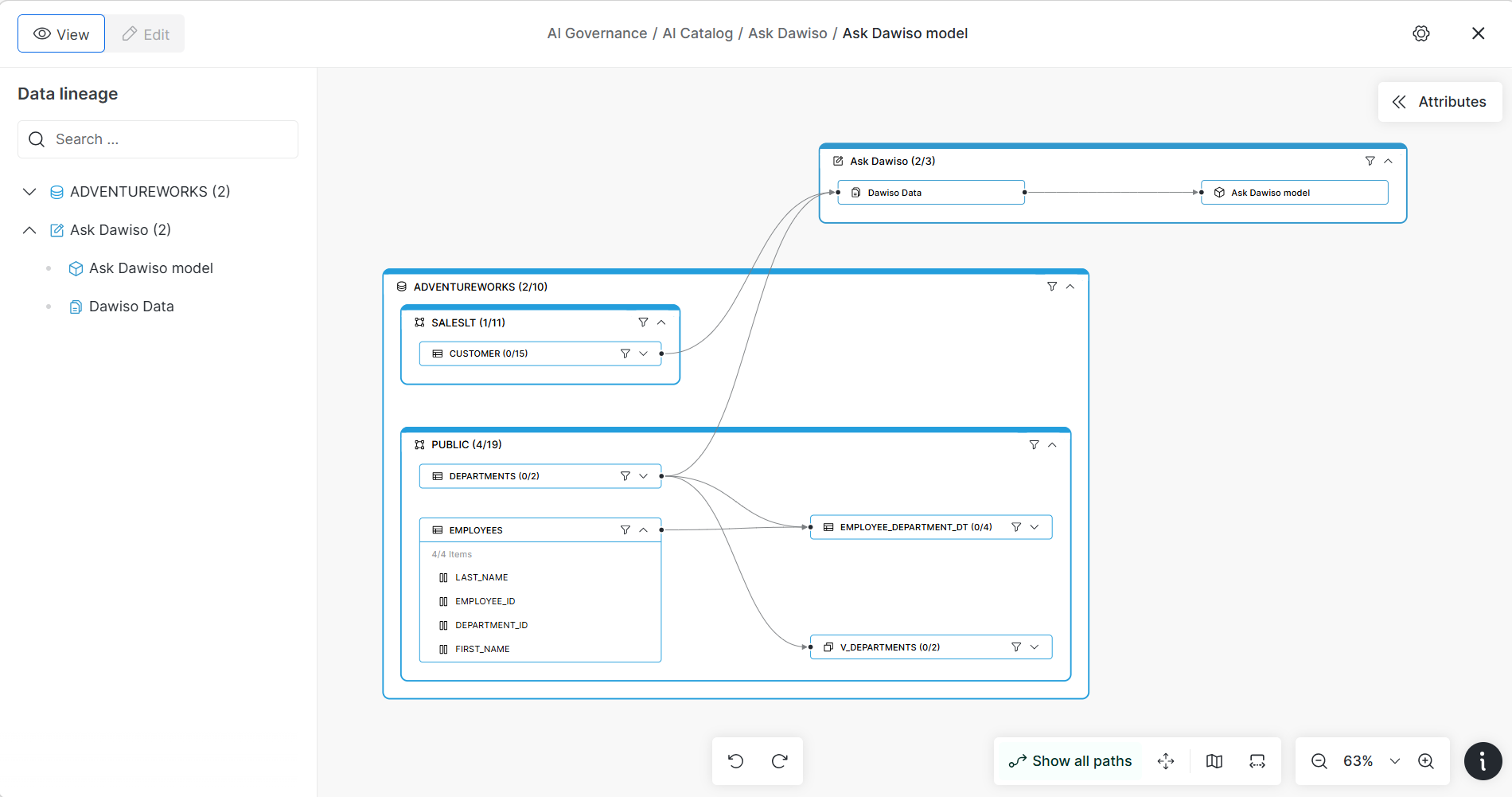
Check 4. Lineage-traced: answers can be trusted and audited
The fourth check is lineage: a traceable map of where the data came from, what transformed it, and what depends on it. Lineage is what lets an AI answer be traced back to a source and lets you see, before a problem reaches the model, that a definition is fed by a pipeline that broke overnight. In the agent era this is not a nicety: an agent acting on an untraceable number is an operational and compliance risk, not just a wrong dashboard.
How to measure it: can you trace any value the AI returns back through its transformations to an authoritative source? If the answer is "probably, if someone reads the pipeline code," this check fails.
Check 5. Quality-scored: the data is good enough to act on
An AI applied to bad data produces fluent, confident, wrong answers faster than any human could. The fifth check is whether the dataset carries measured quality signals across the dimensions that matter (accuracy, completeness, consistency, timeliness), ideally against a recognized model such as ISO/IEC 25012, plus a clear certified-or-deprecated status. Quality is what separates an authoritative source from a stale copy, and the AI has no way to tell them apart on its own.
How to measure it: does the dataset expose freshness, completeness and a certification status the AI (and a human) can check? If "is this data good?" can only be answered by gut feel, this check fails.
Check 6. Owned: someone is accountable
Context without ownership rots. The sixth check is whether the dataset has a named owner and steward: someone accountable for its definitions, its quality, and its access rules. Ownership is what keeps the other six checks true as the business changes: when a definition needs updating or a pipeline shifts, there is a person responsible rather than a diffusion of "someone should fix that." Unowned data drifts away from reality, and an AI keeps trusting it long after it stopped being correct.
How to measure it: can you name the owner and steward of the dataset, and is there an approval workflow for changes to its definitions and policies? If ownership is "the data team, collectively," this check fails.
Check 7. Accessible over MCP: the AI can actually read it
The first six checks govern context. The seventh delivers it. All that meaning, classification, lineage and ownership is worthless to an AI if it stays locked in the tools that hold it. The final check is whether your governed context is exposed through a standard, open channel: the Model Context Protocol (MCP), so that any compatible assistant or agent can read it on demand. Through an MCP Server, your catalog, glossary, classification and lineage become a single endpoint every AI tool can query.
How to measure it: can a new AI tool connect once and read your governed definitions, policies and lineage, or must each tool re-implement them internally? If your context can't leave the tool that built it, this check fails, and you are rebuilding silos one assistant at a time.
How to score your readiness
The checklist is only useful if you apply it. For each dataset an AI will use, rate every check as in place, partial, or missing. A dataset is AI-ready only when all seven are in place; any "missing" is a blind spot where the AI falls back to guessing, and any "partial" is a quiet risk. Most teams find their data clusters around the first two checks (some cataloging, patchy definitions) and thins out toward classification, lineage and delivery, which is also the order in which the failures get expensive.
Use the scorecard below as a template. Run it per domain rather than boiling the ocean: get a handful of high-value datasets to all-seven before widening the net. Readiness is not a one-time grade; re-score as data and definitions change, because a dataset that was AI-ready last quarter drifts the moment its meaning or quality does.
Getting AI-ready with Dawiso
The reason "AI-ready" feels vague is that the seven checks usually live in seven different places, if they exist at all. Dawiso assembles them in one governed layer across more than 40 platforms: a Data Catalog (cataloged), a Business Glossary (defined), classification and policy (classified), Interactive Lineage (lineage-traced), quality and certification signals (quality-scored), and ownership with stewardship workflows (owned). Dawiso AI drafts descriptions and classification for human review, so closing the gaps is configuration, not a multi-quarter build.
The seventh check is what ties it together. Through the Context Layer and its MCP Server, that governed context is served to any MCP-compatible assistant or agent, so your data is AI-ready for every tool at once rather than one integration at a time. If you want the step-by-step build, our companion guide covers how to implement an enterprise context layer for AI. AI-ready data is not a slogan or a property of your model. It is seven properties of your data, and they are properties you can govern.
FAQ
What does "AI-ready data" actually mean?
How do I know if my data is AI-ready?
What's the difference between AI-ready data and good data quality?
Do I need all seven checks, or are some optional?
How does Dawiso make data AI-ready?
See it in action
Dawiso Context Layer
Make your data AI-ready once: cataloged, defined, governed, then serve it to every AI tool over MCP.


