Data Lineage Techniques and Extraction Methods Explained

Enterprises have constructed extensive data infrastructures to capture and handle their constantly expanding volumes of data. However, as data storage grows, the pathways that transport valuable information to the business become less clear, leading to reduced reliability in the resulting data analysis. This underscores the importance of understanding the journey of your data. Are you wondering how data lineage is created? How do we know where the source data comes from and what transformations the data has undergone? If so, read on.
While we have already discussed data lineage in more detail in this article, let's now examine data lineage from a technical perspective.
What is data lineage and how do we create it?
Data lineage is the systematic tracking of data's journey from its origin to its final destination. It provides a comprehensive view of data transformations and dependencies, enabling organizations to improve data quality, streamline processes, and ensure regulatory compliance.
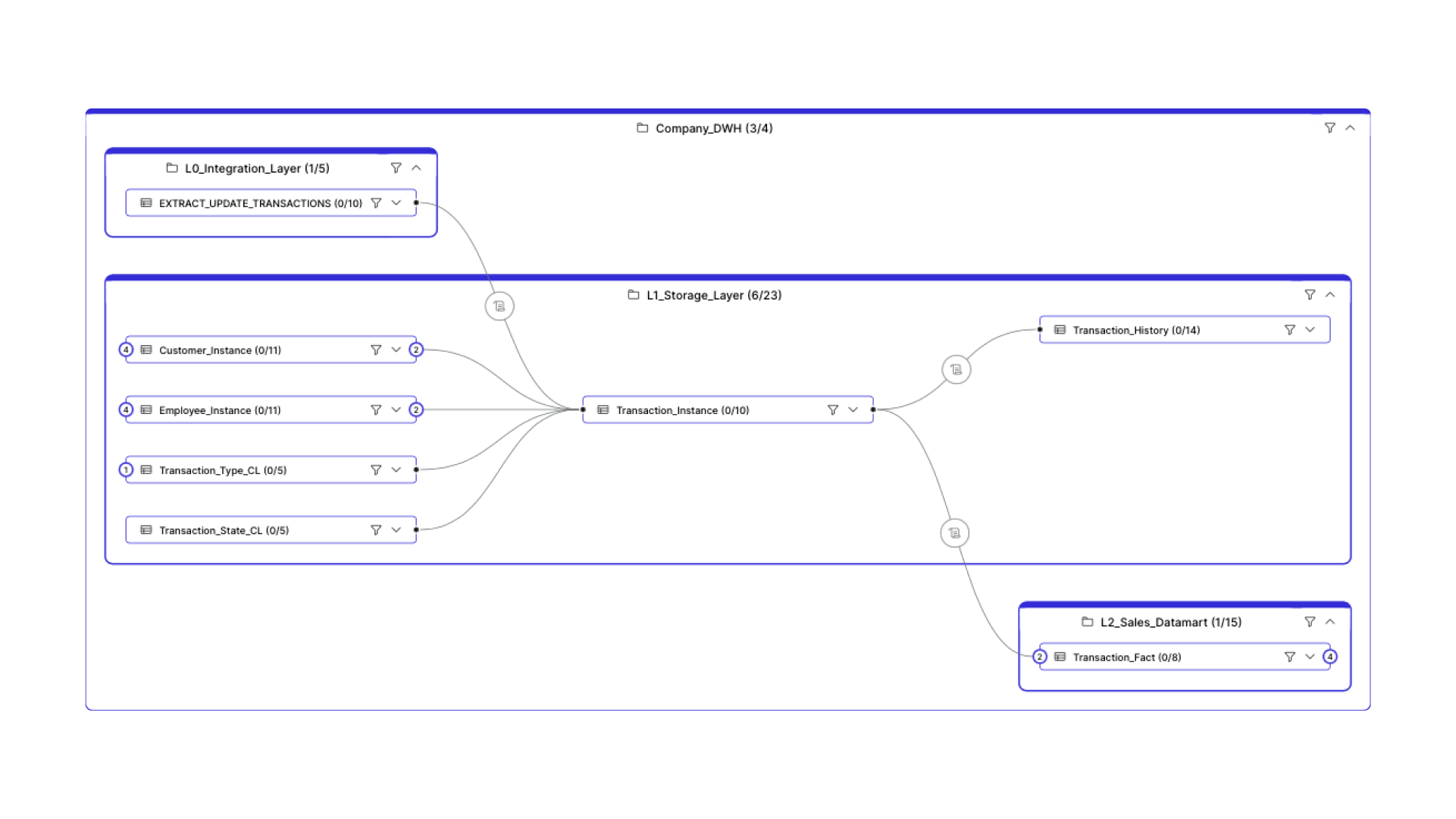
Where does data lineage come from and what do data engineers need to do to track these changes?
You can't build data lineage just from having metadata available. Dawiso, as a metadata platform, scans the entire database where it has all tables, columns etc. available, but it's not possible to draw lineage over them. Even if you have all the objects that should be in a specific lineage, you'll never know how they're connected. Why? Because lineage tells you how the data flows, and scanning a database only gives you a static snapshot. Usually, there's also code available that tells us about the procedures that process it. But even in that case, we don't have that code parsed.
Fundamental Components of Data Lineage
To effectively capture and manage data lineage, two essential elements must be considered:
- Data Objects: These are entities that store data, such as tables, columns, files, or data streams. Data objects serve as the building blocks of lineage.
- Lineage Logic: This component defines the relationships and transformations between data objects. It describes how data flows from one object to another and the processes involved.
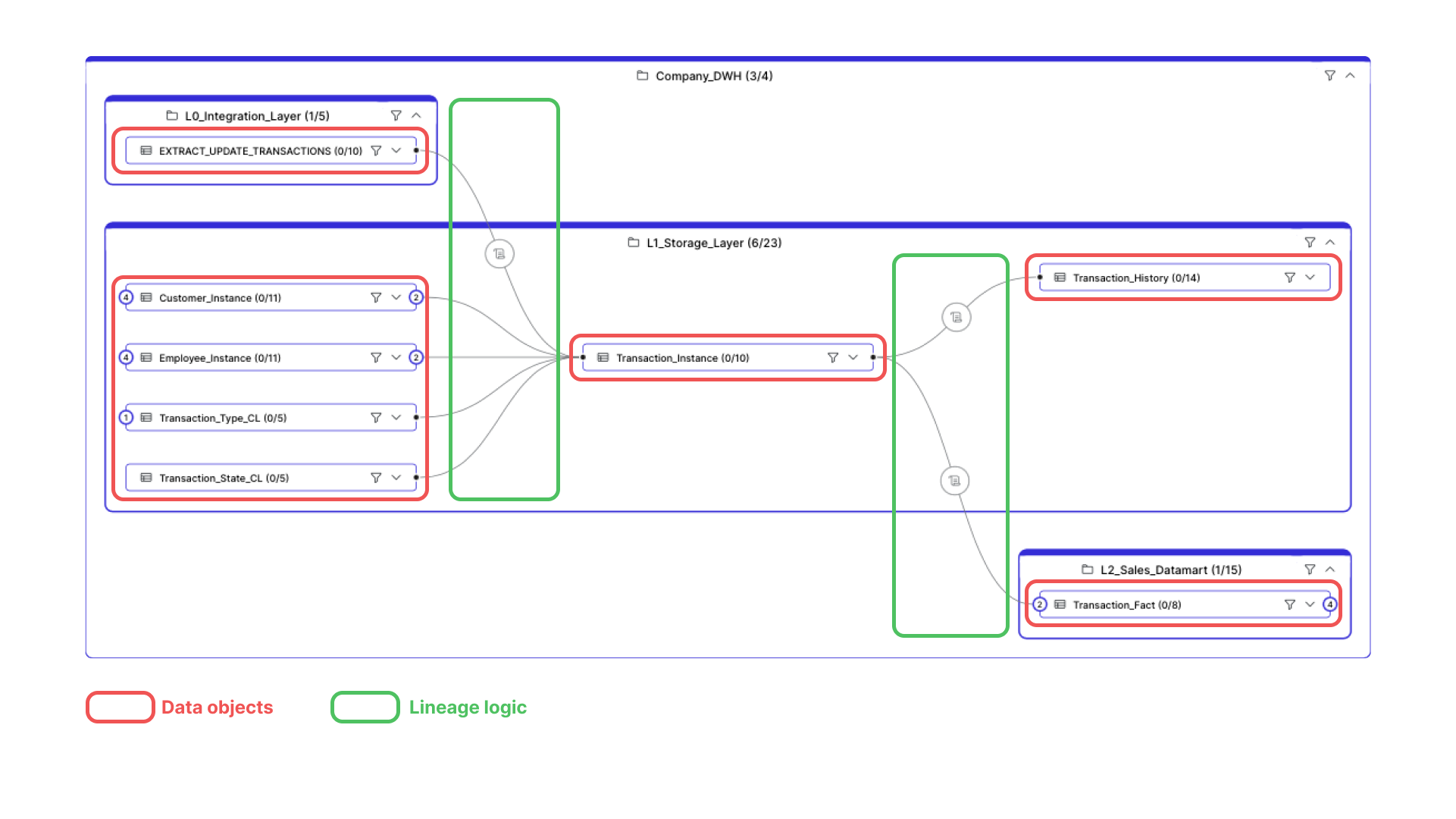
Data Lineage Extraction Methods
As we know, data lineage essentially consists of two fundamental components: data objects themselves and the logic that connects them. We obtain data objects through scanning (metadata). What remains is to incorporate the logic. There are four ways to acquire information about the origin. The first two methods relate to ETL. ETL can either be built in tools like Keboola or written in code by data engineers.
1. Platform-Provided Lineage
The first option is to use a system that has this logic built-in. An example of such software is Keboola, which can provide lineage to Dawiso itself. From this, we get information about the logic between tables, columns etc. - what data objects it has, as well as the logic of how they are connected. It can be easily connected in it, and we can redraw it into our metadata platform. As Dawiso, we are Keboola's first technology partner that provides rendering of Keboola data lineage. This is the most precise and straightforward way to get the necessary information for visualizing data lineage.
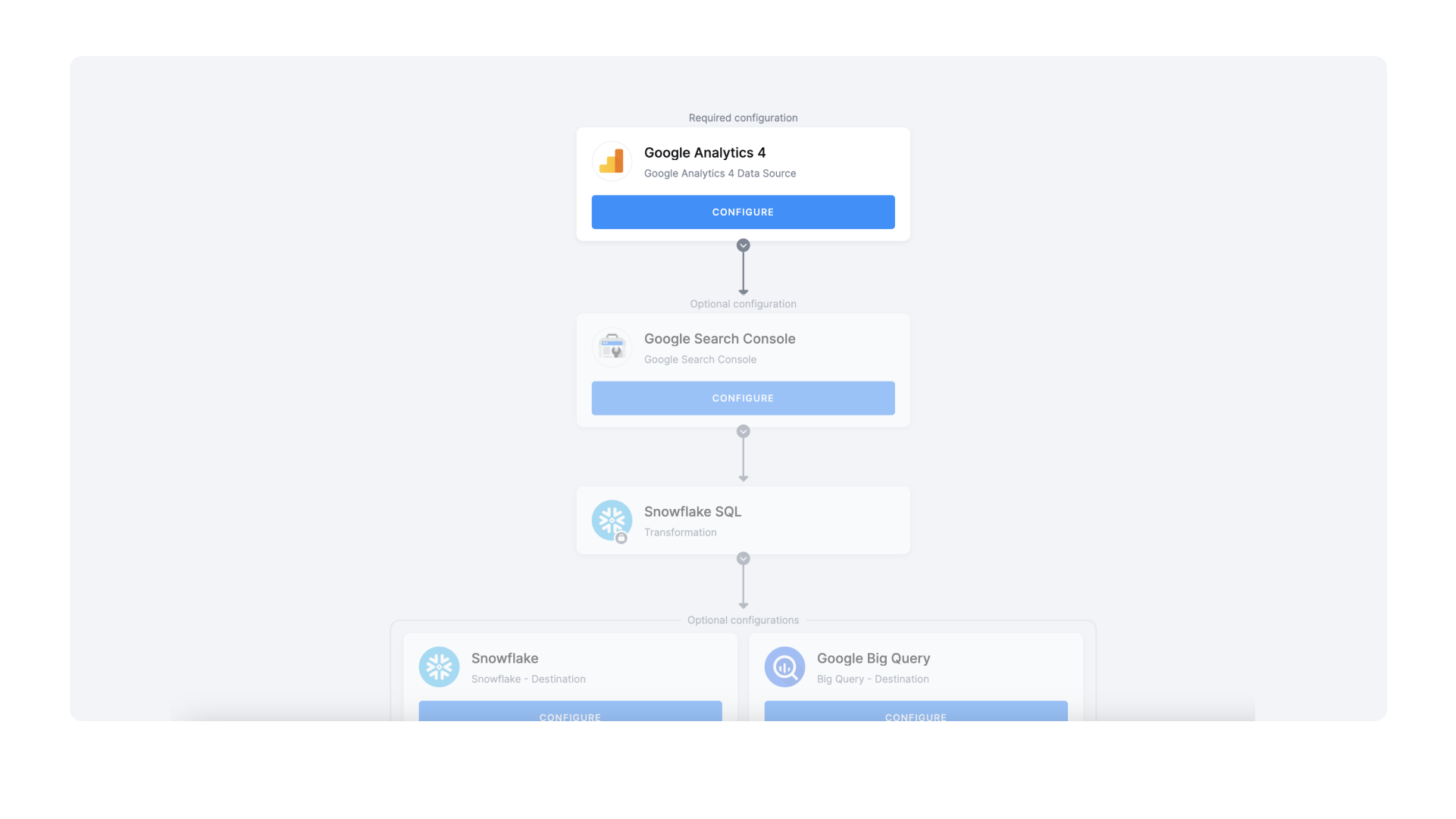
Let's illustrate this with an example. SSIS (SQL Server Integration Services) is an ETL tool directly from Microsoft, developed specifically for Microsoft SQL databases. They work well together. The image shows that the loaded source data (tables and columns), which is then transformed and subsequently stored in another database. This is ETL, but instead of writing it in code, it is built on the frontend (in some graphical interface - which is similar to Keboola). In practice, building this logic looks exactly like the image.
This Manual Data Processing is the first way to build ETL.
2. Development Framework
Development frameworks, such as dbt, provide a structured approach to building and managing data pipelines. These frameworks often incorporate features that facilitate data lineage tracking, but the level of detail and integration can vary.
By connecting to dbt, Dawiso can extract valuable information about data transformations, dependencies, and the flow of data within the pipeline. While more complex than platform-provided information due to the need for a third-party system, this method is still highly precise.
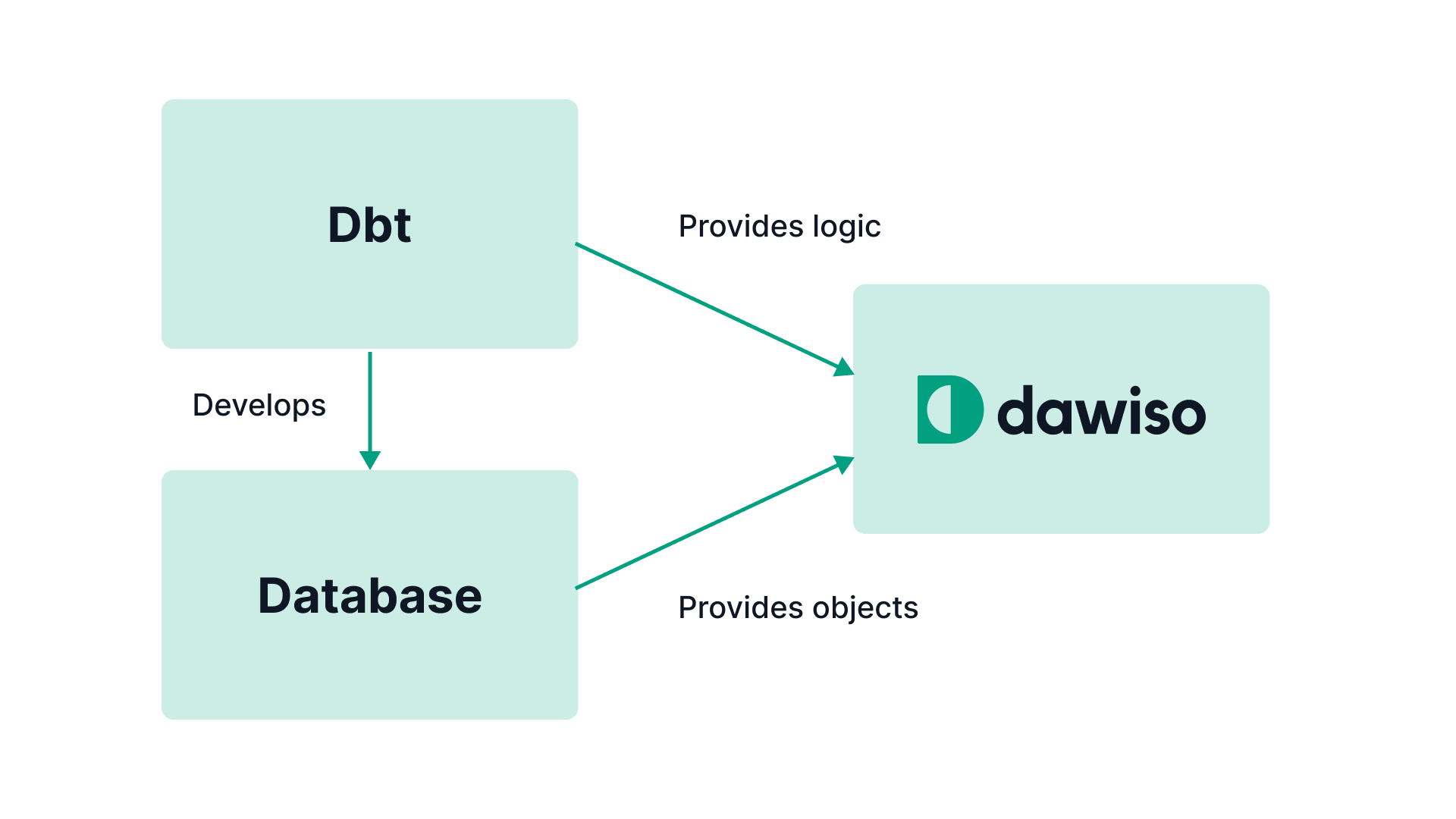
While requiring the involvement of a third-party tool, the framework-based approach to data lineage offers several advantages. It provides a more granular and comprehensive understanding of data transformations, as it can delve into the intricacies of the code and logic used within the development framework. This level of detail can be crucial for tasks like impact analysis, troubleshooting, and compliance reporting.
In some cases, additional tools or configurations may be necessary to fully leverage the framework's lineage potential.
3. Code Parsing Lineage
A third option for obtaining information about data transformations is code analysis (sometimes called code parsing). This is especially useful when these transformations are implemented directly in the database, such as in Oracle. If a development environment lacks tools for automated lineage capture and the underlying technology doesn't provide lineage APIs, SQL code can be parsed to extract data transformation details. This method represents the most sophisticated and at the same time also the most complicated approach to data lineage. It involves automatically analyzing the underlying code to understand how data is processed. By reverse-engineering these processes, it provides a complete picture of data transformations from start to finish.
When scanning a database, we typically encounter these basic objects: tables, views, procedures, and functions. While tables and views contain the actual data, procedures and functions represent the code that performs various operations on this data. Procedures are essentially stored scripts that can perform ETL (Extract, Transform, Load) processes. This means they automatically load data from a source, transform it, and store it in a target.
A disadvantage of this approach is that the code stored in procedures can be difficult to read and requires special tools for analysis. These tools allow us to parse the procedure code and find out what data it processes, where it loads it from, and where it stores it. In other words, we must "generate" the logic of what the procedure does ourselves based on an analysis of its code.

Parsing in text is a process where structured text or data is divided into smaller, more manageable parts. It's like breaking down a sentence into individual words or phrases to better understand its meaning. Code parsing in the context of data focuses on analyzing and extracting information directly from the source code.
Code analysis involves analyzing scripts and code to identify data transformations. By examining SQL scripts, Python code, or other programming languages, it's possible to obtain lineage information directly from the codebase. However, this method can be complex due to the complexities of code logic, such as dynamic SQL and stored procedures.
Dawiso offers optional third-party parsers for SQL code. These parsers support SQL Server, Snowflake, Oracle, BigQuery. However, there might be limitations on the number of lines or scripts processed. Implementing these parsers requires evaluation and coordination with the Dawiso team. Alternatively, clients can provide custom parsers or develop their own solutions to meet specific needs.
4. Manual Data Mapping
The fourth option is that the data transformation logic is not explicitly recorded anywhere or cannot be extracted from the available sources. In such a case, we would have to find this logic manually, for example by studying documentation, interviewing experts, or examining the structure and content of individual tables.
This approach is only practical if we have a relatively small number of tables. As the number of tables increases significantly, manual analysis becomes very time-consuming and prone to errors. In such cases, it is almost impossible to obtain a complete and accurate overview of all data transformations.
Despite this, in some cases, manual mapping of data lineage is necessary. This approach involves creating and maintaining lineage information through human intervention. While time-consuming, manual mapping is often required for legacy systems or when automated methods are not feasible.
Why is data lineage important?
- Enable faster impact studies.
- Data Trust: Ensures data quality and accuracy.
- Error Elimination: Allows easy tracing and correction of errors.
- Audit: Provides evidence of the data used for a specific analysis.
- Data Management: Enables efficient management and maintenance of the data warehouse.
With data lineage, we can always find out where the data in our data warehouse comes from, what changes have been made to it, and what tools were used. This is essential for ensuring data integrity and supporting data-driven decision-making.
Data lineage in the Dawiso system
Dawiso addresses data lineage challenges by combining multiple extraction methods. Our platform leverages ETL tool integration, code analysis techniques, and manual mapping to provide a comprehensive view of data lineage. Key features of the Dawiso system include:
- Support for various data sources
- Visual lineage graphs for easy interpretation
- Impact analysis to assess the consequences of data changes
Data lineage is essential for organizations seeking to understand data impact, and comply with regulations. By addressing the challenges and leveraging appropriate methods, organizations can establish robust data lineage practices. Dawiso offers a powerful solution to help you unlock the full potential of your data through comprehensive lineage management.


